As mentioned in our post “China: Techno-socialism Seasoned with Artificial Intelligence“, in its aim of gaining a global leadership role, China launched the Belt and Road Initiative in 2013: a global infrastructure development strategy to invest in more than 150 countries and international organizations. The BRI was composed of six urban development land corridors linked by road, rail, energy, and digital infrastructure and the Maritime Silk Road, linked by the development of ports.
In 2015, the Chinese government published the “Vision and Actions on Jointly Building Silk Road Economic Belt and 21st Century Maritime Silk Road”, introducing the concept of “Information Silk Road” as a component of BRI -later to be rebranded as “digital’ to encompass its broader aspirations. In 2017, during the BRI Forum in Beijing, Xi Jinping stated the use of AI and big data would be incorporated in the future of BRI as well, further illustrating its broad and ever-evolving nature. The DSR is an important component of China’s Belt and Road Initiative (BRI); it covers a wide array of areas, ranging from telecommunications networks, to ‘Smart City’ projects, to e-commerce, to Chinese satellite navigation systems, and of course AI.
The DSR aims at the global expansion of Chinese technologies to markets in which western players have previously dominated, or in developing countries that are only now undergoing a technological revolution. The implementation of China’s DSR has mainly covered the developing countries of Africa, Asia, Latin America, the Middle East, and Eastern Europe. China presents the DSR as a tool for development, innovation, and technological evolution. However, in its ambitions and impact, the DSR is also a question of geopolitics, as it facilitates China’s attempt to establish itself as a major global power across a growing number of technical and research fields, and regions.
With the growing prominence of the DSR, some Western countries have voiced their concerns about the potential risks related to Chinese technology and involvement in sensitive sectors. Both the US and EU have taken steps to counter the rising influence of the DSR. As a tool to contest the Chinese initiative, the US launched the ‘Clean Network’ initiative. Said that, the EU does not have a unified stance on cooperation with China on the DSR. Among 27 members, there are ‘champions’ of the pushback against China, especially among Central and Eastern European countries like Czechia, Slovakia, Slovenia, and Romania, that have aligned with the US’ initiative. Others, like France, have not introduced outright bans but have de facto decided to exclude “untrusted vendors”, and to focus on the European companies and equipment due to security concerns. Germany, on the contrary, is still considering the inclusion of the Chinese companies in the construction of its 5G infrastructure, for instance.
Western Balkans is a region that has been often seen as a springboard by China regarding its presence in Europe. Chinese efforts to include Serbia in the DSR have been more than welcomed and hence Serbia has become a main stop for the Chinese initiative in the region.
Serbia has developed extensive and strategic relations with China over the past decade. The partnership has also included cooperation within the framework of the DSR. Serbia and China signed the Strategic Agreement on Economic, Technological, and Infrastructural cooperation in 2009. That agreement was a starting point for the development of the contemporary relations between two countries and a cornerstone for future joint projects. During the visit of Chinese leader Xi Jinping to Belgrade in 2016, the two countries established a Comprehensive Strategic Partnership.
DSR has reached Serbia and made it the focal point in the Western Balkans. However, cooperation could come with a price. If Serbia relies too much on China in its technological development and does not differentiate partner companies and suppliers, it may become too dependent on its Chinese partners. The absence of diversification can jeopardize the sustainability of the system and the possibility of further improvements of the system in the future. The need of not being dependent on foreign technology is a lesson perfectly learned and practiced by the Chinese authorities concerning AI.
Chinese Non-dependency Policy Regarding GenAI / LLMs
For China and Chinese companies, developing indigenous LLMs is a matter of independence from foreign technologies and also a matter of national pride. Since August 2023, when China’s rules on generative AI came into effect, 46 different LLMs developed by 44 different companies were approved by the authorities. The legislation requires companies to ensure that the models’ responses align with the communist values and also undergo a security self-assessment, which has, however, not been defined until recently. Besides the afore-mentioned approved models, it is estimated that there are more than 200 different LLMs currently functioning in China.
The first wave of models approved in August 2023 was predominantly general LLM models developed by the biggest players in China’s technological market – Baidu, Tencent, Alibaba, Huawei, iFlytek, SenseTime, and ByteDance. Besides these companies, Chinese research institutions, namely the Chinese Academy of Sciences and Shanghai Artificial Intelligence Laboratory, received approvals for their models. In the following batches, models with specific applications started to appear: models designed for recruitment purposes -ranging from CV formatting to providing recommendations; models designed to help companies with cyber security assessments and risk prevention; models designed for readers to interact with their favorite literary characters; models aimed at video content generation based on an article or an idea description; and models providing recommendations to customers and serve as AI assistants.
In March 2024, China’s National Information Security Standardization Technical Committee (TC260) published its basic security requirements for generative AI, which qualifies as a technical document providing detailed guidance for authorities and providers of AI services. This text sets measures regarding the security of training data. Providers must randomly choose 4,000 data points from each training corpus and the number of ‘illegal’ or ‘harmful’ information should not exceed five percent. Otherwise, the corpus may not be used for training. Developers are also required to maintain information about the sources of the training data and the collection processes, and acquire agreement or other authorization to use data for training when using open-source data. This document also provides detailed guidance regarding the evaluation of the model’s responses. Providers are required to create a 2,000-question bank designed to control the model’s outputs in the case of areas defined as “security risks.” -everything which might mean a violation or threat to the communist values.
Importantly and as final note concerning the willingness of being independent from foreign technical developments, the newest AI rules stipulate that Chinese companies are not allowed to use unregistered third-party foundation models to provide public services. This means that access to LLMs developed outside China becomes even more limited and some of the Chinese AI companies who have built their applications based on ChatGPT or LlaMa, for instance, will need to find other solutions.
More than ever the geopolitical battlefield is played mainly on the technological / AI realm.
“Yes, but artificial intelligence must become common currency”.
A few days ago I had the good fortune to attend a meeting between technology investors, entrepreneurs, businessmen and professors in the field, the latter three, of AI. It was interesting, on the one hand, to mix in the same virtual space money, willingness to create something, success in having done so, and knowledge… and, on the other hand, to observe the same vital dilemma regarding this technology is shared in the background: democratization or industrialization of artificial intelligence.
Information and communication technologies -and more specifically AI- are GPTs, general purpose technologies, a term coined by MIT professors Erik Brynjolfsson and Andrew McAfee in their book The Second Machine Age; namely, technologies that “disrupt and accelerate the normal march of economic progress”. The steam engine and electricity were also GPTs. They were disruptive technologies that have extended their reach into many corners of the economy and radically altered the way we live and work.
Nonetheless, if we look at the current state of AI, it has yet to take off. Why? One of the reasons is perhaps because it is stuck at a crossroads.
On the one hand, we have tech giants like Amazon, Google, Facebook, Alibaba, Tencent… they are not only competing with each other to see which is the first to discover the next disruptive breakthrough within AI. At the same time, they compete against fast AI startups that want to use machine learning, deep learning, ontologies or even hybrid approaches -mathematics, statistics, rule-based programming and logic…-, to revolutionize certain specific industries. It is a competition between two approaches to extend AI in the field of economics: the industrialization of the powerful giants versus the democratization of the agile startups. How that race plays out will determine the nature of the AI business landscape: monopoly, oligopoly, or free and spontaneous competition amongst thousands of companies. The industrialization approach wants to turn AI into a commodity, with a price tending towards zero. Its goal is to transform the power of AI, and its various subfields, into a standardized freemium service; namely, any company can acquire it, with its use perhaps being free of charge for academic or personal environments. Access to this freemium AI environment would be through cloud platforms. The powerful giants behind these platforms (Google, Alibaba, Amazon…) act as service companies, managing the network and charging a fee. Connecting to that network would allow traditional companies, with a large data set, to leverage the optimization power of AI without having to redo their entire business. The most obvious example of this approach: Google’s TensorFlow. This is an open-source software ecosystem for building deep learning models; however, it still requires specialized programming skills to make it work. The goal of the network approach is to both lower that specialization threshold and increase the functionality of AI platforms in the cloud. Making full use of an AI model is not easy as of today but AI giants hope to simplify this technology and then reap the rewards, in addition to operating the network.
On the other hand, AI start-ups and middle-sized enterprises (MsEs) are taking the opposite approach. Instead of waiting for this network to take shape, they are creating AI niche products for each use case. Such startups and MsEs are aiming at specialization, rather than breadth. Instead of providing, for example, natural language processing models for general purposes, they build new products, solutions, niche platforms for algorithms to perform specific tasks such as fraud tracking, insurance policy comparison, customer profiling for upselling and cross-selling, terrorist threat detection on social networks, pharma knowledge graph generation… The starting postulates of these startups and MsEs are twofold: on the one hand, traditional businesses are still very far, operationally, from being able to use a multipurpose AI network; on the other hand, AI should start to be an intrinsic element in the business operation of these traditional companies. It is because of the latter that, almost always, companies following this approach end up building a strategic relationship with the AI startup or MsE, which has introduced them to this world.
Who will win in this race? Difficult to make a prediction. What is clear is that, if the industrialization approach triumphs, the astronomical economic benefits of this technology will be concentrated in a handful of companies (probably American and Chinese ones); if the democratization approach succeeds, these huge benefits will be spread among thousands of vibrant young agile companies.
El blanqueo de capitales se define legalmente como la transferencia de dinero obtenido ilegalmente a través de personas o cuentas legítimas, de manera que no se pueda rastrear su fuente original.
El Fondo Monetario Internacional (FMI) estima que el tamaño agregado del blanqueo de capitales en todo el mundo es de aproximadamente 3,2 billones de dólares, o el 3% del PIB mundial. Los beneficios del blanqueo de capitales se utilizan a menudo para financiar delitos, como el terrorismo, la trata de personas, el tráfico de drogas y la venta ilegal de armas. Los bancos y otro tipo de instituciones financieras implementan sistemas contra el blanqueo de capitales. No cumplir con las normas de lucha contra el blanqueo de capitales es un tipo de delito corporativo, que significa un serio riesgo para la reputación de estas instituciones financieras. A pesar de los esfuerzos actuales, varias instituciones financieras multinacionales han sido objeto de fuertes multas por parte de los reguladores de la lucha contra el blanqueo de capitales, por la ineficacia de sus prácticas en los últimos años.
La introducción de la inteligencia artificial con el propósito de luchar contra el blanqueo de capitales mejora y facilita el proceso general de toma de decisiones, al tiempo que se mantiene el cumplimiento de políticas como el Reglamento General de Protección de Datos. La IA puede reducir al mínimo el número de transacciones falsamente etiquetadas como sospechosas, lograr una calidad demostrable de cumplimiento de las expectativas reglamentarias, y mejorar la productividad de los recursos operacionales.
La colocación, la diversificación y la integración son las tres fases en los procesos de blanqueo de capitales. En la fase de colocación el producto de las actividades delictivas se convierte en instrumentos monetarios o se deposita de otro modo en una institución financiera (o ambas situaciones). La diversificación se refiere a la transferencia de fondos a otras instituciones financieras o personas mediante transferencias electrónicas, cheques, giros postales u otros métodos. En la fase final de integración, los fondos se utilizan para adquirir activos legítimos o seguir financiando empresas delictivas. En este caso, el dinero obtenido ilegalmente pasa a formar parte de la economía legítima. Los enfoques de inteligencia artificial pueden aplicarse para identificar las actividades de blanqueo de capitales en cada una de las tres fases mencionadas. Pueden utilizarse métodos comunes de aprendizaje automático como las máquinas de vectores de soporte (support vector machines, según su denominación en inglés), y los bosques aleatorios (random forests, según su denominación en inglés), a fin de clasificar las transacciones fraudulentas utilizando grandes conjuntos de datos bancarios anotados.
En la actualidad, los esquemas típicos en la lucha contra el blanqueo de capitales pueden descomponerse en cuatro capas. La primera capa es la capa de datos, en la que se produce la recogida, gestión y almacenamiento de los datos relevantes. Esto incluye tanto los datos internos de la institución financiera como los datos externos de fuentes como agencias reguladoras, autoridades y listas de vigilancia. La segunda capa, la capa de control y vigilancia, examina las transacciones y los clientes en busca de actividades sospechosas. Esta capa ha sido automatizada en su mayor parte por las instituciones financieras en un procedimiento de varias etapas que a menudo se basa en normas o análisis de riesgos. Si se encuentra una actividad sospechosa, se pasa a la capa de alerta y eventos para una inspección en más detalle. El aprovechamiento de los datos en redes sociales y la web para adquirir información para la investigación está poco desarrollado en los sistemas actuales de lucha contra el blanqueo de capitales. Un analista humano toma la decisión de bloquear o aprobar una transacción en la capa de operaciones.
Procesamiento de lenguaje natural, ingeniería ontológica, aprendizaje automático, aprendizaje profundo y análisis de sentimiento
El procesamiento de lenguaje natural (PLN) y la ingeniería ontológica, ambos campos de la inteligencia artificial, pueden ayudar a aliviar la carga de trabajo al proporcionar a los expertos humanos una valoración y una visualización de las relaciones, basadas en datos de las noticias: por ejemplo, la base de datos de noticias de los bancos y las fuentes de noticias tradicionales o de las redes sociales en relación con la posible entidad defraudadora. Un enfoque para identificar el blanqueo de capitales consiste en definir un grafo de conocimiento relativo a las entidades. El reconocimiento de entidades es un conjunto de algoritmos capaces de reconocer las entidades pertinentes; a saber, personas, cargos y empresas mencionadas en una cadena de texto de entrada. La extracción de relaciones detecta la relación entre dos entidades nombradas (e1 , e2) en una oración dada, típicamente expresada como un triplete [ e1 , r, e2 ] donde r es una relación entre e1 y e2. La resolución de entidades determina si las referencias a las entidades mencionadas en diversos registros y documentos se refieren a la misma o a diferentes entidades. Por ejemplo, una misma persona puede ser mencionada de diferentes maneras, y una organización podría tener diferentes direcciones. Los principales desafíos en el aprendizaje de grafos para la lucha contra el blanqueo de capitales son la velocidad de aprendizaje/análisis de grafos y el tamaño de los mismos. El aprendizaje rápido de grafos utiliza redes neuronales convolucionales rápidas, y aumenta drásticamente las velocidades de entrenamiento en comparación con las redes neuronales convolucionales convencionales. El análisis de relaciones, de sentimiento y muchas otras técnicas basadas en el PLN y los grafos de conocimiento se utilizan a menudo para reducir los altos índices de falsos positivos en la lucha contra el blanqueo de capitales.
Otra manera de enmarcar la IA y la minería de datos en la lucha contra el blanqueo de capitales es a través de la detección de anomalías mediante técnicas de aprendizaje automático. De conformidad con este método, en primer lugar se define lo que sería una transacción normal o típica y luego se detecta cualquier transacción que sea lo suficientemente diferente como para ser considerada como anómala. Se define un grupo de elementos comunes, a fin de captar los hábitos de gasto típicos de un cliente. La agrupación es un método estándar para definir los grupos de elementos comunes; a continuación, se calcula una distancia entre las transacciones entrantes y los grupos de elementos comunes con el ánimo de detectar comportamientos anómalos, por ejemplo, mediante el algoritmo de agrupación k-medias (k-means, según su denominación en inglés).
El salto adelante significativo se ha producido al utilizar, en contraste con los enfoques convencionales de aprendizaje automático, métodos de aprendizaje profundo para aprender representaciones de características a partir de datos en bruto. En las técnicas de aprendizaje profundo, se aprenden múltiples capas de representación a partir de una capa de entrada de datos en bruto, utilizando manipulaciones no lineales en cada nivel de aprendizaje de la representación. El PLN y el aprendizaje profundo ya se utilizan en muchos niveles de cumplimiento normativo de la lucha contra el blanqueo de capitales.
La implementación de análisis de sentimiento puede ser útil también para la lucha contra el blanqueo de capitales. Entendido dicho análisis como una tarea de clasificación masiva, mediante PLN, de documentos de manera automática en función de la connotación positiva o negativa del lenguaje del documento, su función principal es acortar el período de investigación por parte de un responsable de cumplimiento normativo. Puede aplicarse en diferentes niveles, incluidas las etapas de gestión de atrasos, incorporación de clientes y supervisión del perfil de los mismos. El objetivo de un sistema de análisis de sentimiento en este contexto es vigilar las tendencias de sentimiento asociadas con un cliente, para identificar patrones importantes. Cuando los investigadores de la lucha contra el blanqueo de capitales identifican una empresa que ha participado potencialmente en una transacción sospechosa, generalmente consultan Internet para obtener pruebas. El análisis de los niveles de sentimiento de las noticias relativas a una organización específica puede revelar una gran cantidad de pruebas. El análisis de sentimiento basado en el PLN puede examinar miles de artículos en segundos, mejorando significativamente el proceso de investigación en términos de eficiencia y precisión. El análisis de sentimiento también puede emplearse en el proceso de monitoreo del perfil del cliente y de la incorporación del mismo, con el ánimo de investigar e identificar puntos débiles específicos de un cliente y sus vinculaciones con artículos negativos. En términos de IA, se han utilizado numerosas técnicas para el análisis de sentimiento, entre ellas las máquinas de vectores de soporte, los campos aleatorios condicionales (conditional random fields, según su denominación en inglés) y las redes neuronales profundas como las redes neuronales convolucionales y las redes neuronales recurrentes.
Métodos explicables de inteligencia artificial
La eficacia de los sistemas de IA está limitada en cierta medida por su capacidad para explicar una decisión específica que se ha tomado o predicho. La naturaleza de la explicación varía según las diferencias de los datos y los algoritmos, y hasta ahora no se ha implementado ningún marco común o estándar de explicación.
La comunicación con los analistas es de suma importancia cuando se diseña cualquier sistema de lucha contra el blanqueo de capitales, puesto que los usuarios toman la decisión final. Los métodos explicables de IA funcionan proporcionando a los usuarios información clara sobre por qué se hizo una predicción: por ejemplo, por qué el sistema cree que una transacción es sospechosa, a fin de ayudar a los usuarios a tomar una decisión y fomentar la comprensión de la tecnología por parte de los mismos. Es importante que cualquier sistema pueda explicar sus decisiones de manera sencilla para el usuario. Las políticas europeas y el Reglamento General de Protección de Datos hacen hincapié en la necesidad de que las instituciones financieras proporcionen decisiones explicables y autorizadas por el ser humano. Es fundamental que cualquier método de lucha contra el blanqueo de capitales incorpore un analista humano y garantice que éste comprenda claramente la información que se le presenta. Un sistema de “caja negra” que etiqueta una transacción como “fraudulenta” sin ningún tipo de explicación o argumentación es inaceptable.
Finalmente, en este futuro entorno de trabajo común, una decisión final tomada por el humano, que puede o no apoyar la predicción del sistema, debería ser retro-propagada al modelo de IA para mejorar su capacidad de toma de decisiones. Los sistemas de lucha contra el blanqueo de capitales no deberían ser lineales sino cíclicos, en los que los modelos de IA se comuniquen y aprendan de los analistas. Sólo a través de este esfuerzo conjunto de los seres humanos y la inteligencia artificial los procedimientos de lucha contra el blanqueo de capitales lograrán un éxito excepcional.
Es la capacidad de generar nuevas ideas a partir de asociaciones entre conceptos conocidos, que habitualmente producen soluciones originales. La creatividad tiene que ver con elecciones conscientes o inconscientes, y no con un comportamiento aleatorio.
Para Margaret Boden, filósofa, psicóloga, médico, experta en IA y científica cognitiva, hay tres tipos diferentes de creatividad humana.
La creatividad exploratoria consiste en considerar lo que ya está ahí y explorar sus fronteras exteriores, ampliando los límites de lo que es posible pero permaneciendo a la vez sujeta a las reglas. Las composiciones musicales de Bach y la pintura de Claude Monet son ejemplos de creatividad exploratoria.
La creatividad combinatoria: en la que, a partir de dos configuraciones completamente diferentes, se busca como resultado la combinación de las mismas. Las composiciones del músico Philip Glass o los diseños de la arquitecta Zaha Hadid disfrutan de esta creatividad.
La creatividad transformadora es la más misteriosa y esquiva. Son esos raros momentos en los que cambian por completo las reglas del juego. Por ejemplo: Picasso y el cubismo, Schönberg y la atonalidad, Joyce y el modernismo.
EMI, AIVA, AARON y otros algoritmos del montón
Uno de los problemas que existe al mezclar las ciencias de la computación con las artes creativas es que aquéllas florecen al calor de una filosofía de resolución de problemas. Pero crear una obra de arte no es resolver un problema.
En 1973 Harold Cohen creó AARON, un programa para producir obras de arte. Este programa era del tipo “si… entonces…”; a saber, de los pensados con la estrategia de programación “de arriba abajo”. La toma de decisiones que, según Cohen, llevaba a cabo el ordenador se basaba en el uso de un generador de números aleatorios. Cohen recurrió al poder del azar para crear una sensación de autonomía o capacidad de actuar en la máquina.
En 1983 el compositor y científico estadounidense David Cope construyó el software para generación musical EMI (Experiments in Musical Intelligence), utilizando también un proceso de programación de arriba abajo. EMI dependía de que hubiera un compositor que preparase la base de datos. La creatividad de EMI provenía de Cope y del catálogo que tenía detrás, con las obras de los grandes genios musicales de la historia.
¿Qué nuevas obras artísticas podrían surgir al utilizar el modo de programación de “abajo a arriba”, característico del aprendizaje automático? ¿Podrían los algoritmos tener creatividad transformadora, aprendiendo del arte pasado y llevando la creatividad hasta nuevos horizontes? El aprendizaje automático no requiere que el programador entienda cómo compuso Bach sus corales, porque el algoritmo puede tomar los datos y aprender por sí mismo.
En 2002 François Pachet creó el primer improvisador de jazz con IA usando cadenas de Markov, un tipo especial de proceso estocástico discreto en el que la probabilidad de que ocurra un evento depende solamente del evento inmediatamente anterior. La idea de Pachet era considerar los riffs de los músicos de jazz y, dada una nota, analizar la probabilidad de la nota siguiente. El algoritmo se acabó conociendo como “El continuador”, ya que continuaba tocando en el estilo de la persona que se ocupaba de alimentar su base de datos. Después de cada nota, “El continuador” calculaba hacia dónde dirigirse, basándose en lo que acaba de tocar y en lo que su base de datos decía sobre las probabilidades de que surgieran en ese momento unas u otras notas. He aquí un algoritmo que mostraba poseer creatividad exploratoria.
En 2016 un algoritmo llamado AIVA fue la primera máquina admitida, a título de compositora, en la Société des auteurs, compositerus et éditerus de musique de Francia. El algoritmo combinó el aprendizaje automático con los repertorios de Bach, Beethoven, Mozart y otros para producir un compositor con inteligencia artificial, que estaba creando su propia música original.
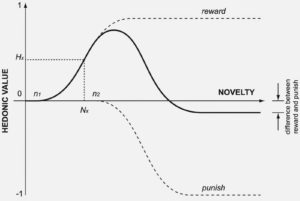
De conformidad con las investigaciones de algunos neurocientíficos, nuestros cerebros mantienen en marcha dos sistemas rivales, como los algoritmos que regulan las redes generativas antagónicas: uno rige el afán exhibicionista por hacer cosas, crear, expresar; el otro es un inhibidor, el “yo” crítico que arroja dudas sobre nuestras ideas, que las evalúa. Según la curva de Wundt, si nos acostumbramos demasiado a las obras de arte que nos rodean, acabamos sumidos en la indiferencia y el aburrimiento. Por eso los artistas nunca se estancan en su trabajo: lo que estimula al artista (y finalmente al espectador) son las cosas distintas. El reto es que el impulso hacia lo provocativo o disonante no sea tan intenso como para alcanzar la pendiente cuesta debajo de la curva de Wundt. Hay un valor hedónico máximo al que el artista debe aspirar:
Curva de Wundt.
En 2017 el profesor Elgammal y su equipo programaron el algoritmo “Generador” de modo que estuviera incentivado para crear obras que pudieran aspirar a alcanzar el punto más alto de la curva de Wundt. El juego consistía en maximizar la diferencia tratando a la vez de no alejarse demasiado de aquellos estilos que el mundo del arte había juzgado aceptables. La tarea del algoritmo “Discriminador”, programado también por el equipo de Elgammal, consistía en avisar al algoritmo “Generador” cada vez que éste se alejaba de lo que se consideraba arte por caer en lo vulgar o lo disparatado. Cada evaluación iba acompañada de una modificación de los parámetros del algoritmo “Generador”. El objetivo era que el algoritmo “Generador” acabara por crear nuevas obras que cayeran en la zona óptima de la curva de Wundt. Elgammal llamó a estas redes, redes creativas antagónicas. Estos algoritmos de redes antagónicas pueden empujarnos hacia nuevos territorios que reconocemos como arte pero que hasta ahora no nos hemos atrevido a explorar.
Retrato de un mercader sin cara. Obra producida mediante Generador y Discriminador.
¿Será posible para una máquina acercarse a los humanos cuando pintan, componen o escriben? Las decisiones que toma un artista se deben en cierto sentido a respuestas algorítmicas del cuerpo ante el mundo que le rodea. ¿Será alguna vez fácil para una máquina producir respuestas tan ricas y complejas como las que produce la programación humana? La programación humana ha evolucionado durante millones de años. La cuestión es ¿hasta qué punto se puede acelerar esa evolución?
Por el momento, toda la creatividad de las máquinas arranca del programa humano. No vemos máquinas que sientan el impulso de expresarse. En realidad, no parece que tengan nada que decir, más allá de lo que nosotros les indicamos que digan o hagan. Nuestra creatividad está íntimamente ligada al libre albedrío, algo que parece imposible de automatizar. Programar el libre albedrío supondría contradecir el significado mismo del término.
Aquello que llamamos obras de arte, sea música, pintura o poesía, son casi productos derivados de ese acto de creación del yo. Mientras una máquina no adquiera consciencia, no será nada más que una herramienta para entender y extender la creatividad humana. ¿Tenemos alguna idea de lo que habrá que hacer para que una máquina adquiera consciencia? Probablemente será necesario recurrir a todas las ciencias en su conjunto para conseguirlo. Y una vez que se consiga, es muy probable que la consciencia de las máquinas sea muy distinta a la nuestra. Tal vez, en ese momento las artes creativas (la pintura, la música, la literatura e incluso las matemáticas) sean la clave para dar acceso recíproco al conocimiento de qué se siente al ser lo que cada cual es.
In 2020, the AI Forum Live was born. This comprehensive digital event is bringing together AI leaders and experts to learn more about cutting-edge artificial intelligence strategies and solutions. Organised by Associazione Italiana per l’Intelligenza Artificiale (AIxIA), which promotes the study and research of AI, this live forum is reuniting the world of research with that of businesses in hopes of building promising new collaborations.
Expert.ai Managing Director – SwitzerlandDomingo Senise de Gracia, will partake in a workshop on November 3rd at 12.30 pm CET to discuss expert.ai’s international expansion and new venture in Switzerland. The presentation will share the main challenges and opportunities expert.ai considered when choosing Switzerland as a strategic environment to leverage and deploy its AI approach.