For much time it seemed that in the computing landscape the main application of graphs were only related to ontology engineering, so when my colleague Mihael shared with me the paper “Graph of Thoughts: Solving Elaborate Problems with Large Language Models” -published by the end of August-, I thought we might be in the right path to re-discover the power to representing knowledge of these structures. In the afore-mentioned paper, the authors harness the graph abstraction as a key mechanism that enhances prompting capabilities in LLMs.
Prompt engineering is one of the central new domains of the large language model research. However, designing effective prompts is a challenging task. Graph of Thoughts (GoT) is a new paradigm that enables the LLM to solve different tasks effectively without any model updates.The key idea is to model the LLM reasoning as a graph, where thoughts are vertices and dependencies between thoughts are edges.
Human’s task solving is often non-linear, and it involves combining intermediate solutions into final ones, or changing the flow of reasoning upon discovering new in sights. For example, a person could explore a certain chain of reasoning, backtrack and start a new one, then realize that a certain idea from the previous chain could be combined with the currently explored one, and merge them both into a new solution, taking advantage of their strengths and eliminating their weaknesses. GoT reflects this, so to say, anarchic reason process with its graph structure.
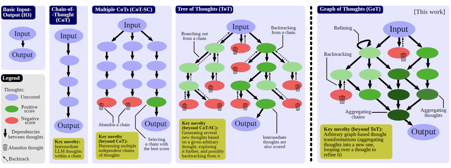
Nonetheless, let’s take a step back: besides Graph of Thoughts, there are other approaches for prompting:
Input-Output (IO): a straightforward approach in which we use an LLM to turn an input sequence x into the output y directly, without any intermediate thoughts.
Chain-of-Thought (CoT): one introduces intermediate thoughts a1, a2,… between x and y. This strategy was shown to significantly enhance various LLM tasks over the plain IO baseline, such as mathematical puzzles or general mathematical reasoning.
Multiple CoTs: generating several (independent) k CoTs, and returning the one with the best output, according to certain metrics.
Tree of Thoughts (ToT): it enhances Multiple CoTs by modeling the process of reasoning as a tree of thoughts. A single tree node represents a partial solution. Based on a given node, the thought generator constructs a given number k of new nodes. Then, the state evaluator generates scores for each such new node.
Explained in a more visual way:
Image taken from the paper “Graph of Thoughts: Solving Elaborate Problems with Large Language Models”
The design and implementation of GoT, according to the authors, consists of four main components: the Prompter, the Parser, the Graph Reasoning Schedule (GRS), and the Thought Transformer:
The Prompter prepares the prompt to be sent to the LLM, using a use-case specific graph encoding.
The Parser extracts information from the LLM’s thoughts, and updates the graph structure accordingly.
The GRS specifies the graph decomposition of a given task, i.e., it prescribes the transformations to be applied to LLM thoughts, together with their order and dependencies.
The Thought Transformer applies the transformations to the graph, such as aggregation, generation, refinement, or backtracking.
Finally, the authors evaluate GoT on four use cases -sorting, keyword counting, set operations, and document merging-, and compare it to other prompting schemes in terms of quality, cost, latency, and volume. The authors show that GoT outperforms other schemes, especially for tasks that can be naturally decomposed into smaller subtasks, are solved individually, and then merged for a final solution.
Summing up, another breath of fresh air in this hecticly evolving world of AI; this time combining abstract reasoning, linguistics, and computer sciences. Pas mal at all.
Much has been stated about the impact of Generative AI on the workforce for the past months, and many more pages will be written in the coming ones.
Last September, 15th 2023, appeared the paper “Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on KnowledgeWorker Productivity and Quality” by, amongst others, Harvard Business School and MIT Sloan School of Management. Some months in advance -in June- McKinsey & Company published a meaningful report titled “The Economic Potential of Generative AI”
Some of the thoughts exposed in them are worthy to be pondered.
The paper by Harvard Business School and MIT Sloan School of Management examined the performance implications of AI on complex knowledge-intensive tasks, using controlled field experiments with highly skilled professionals. The experiments involved two sets of tasks: one inside and one outside the potential technological frontier of GPT-4, OpenAI large language model. The participants were randomly assigned to one of three experimental conditions: no AI, AI only, or AI plus overview. The “overview condition” provided participants with additional materials that explained the strengths and limitations of GPT-4, as well as effective usage strategies.
Understanding the implications of LLMs for the work of organizations and individuals has taken on urgency among scholars, workers, companies, and even governments. Outside of their technical differences from previous forms of machine learning, there are three aspects of LLMs that suggest they will have a much more rapid, and widespread impact on work.
The first is that LLMs have surprising capabilities that they were not specifically created to have, and ones that are growing rapidly over time as model size and quality improve. Trained as general models, LLMs nonetheless demonstrate specialist knowledge and abilities as part of their training process and during normal use.
The general ability of LLMs to solve domain-specific problems leads to the second differentiating factor of LLMs compared to previous approaches to AI: their ability to directly increase the performance of workers who use these systems, without the need for substantial organizational or technological investment. Early studies of the new generation of LLMs suggest direct performance increases from using AI, especially for writing tasks and programming, as well as for ideation and creative work. As a result, the effects of AI are expected to be higher on the most creative, highly paid, and highly educated workers.
The final relevant characteristic of LLMs is their relative opacity. The advantages of AI, while substantial, are similarly unclear to users. It performs well at some jobs, and fails in other circumstances in ways that are difficult to predict in advance.
Taken together, these three factors suggest that currently the value and downsides of AI may be difficult for workers and organizations to grasp. Some unexpected tasks (like idea generation) are easy for AI, while other tasks that seem to be easy for machines to do (like basic math) are challenges for some LLMs. This creates an uneven blurred frontier, in which tasks that appear to be of similar difficulty may either be performed better or worse by humans using AI.
The future of understanding how AI impacts work involves understanding how human interaction with AI changes depending on where tasks are placed on this frontier, and how the frontier will change over time. The current generation of LLMs are highly capable of causing significant increases in quality and productivity, or even completely automating some tasks, but the actual tasks that AI can do are surprising and not immediately obvious to individuals or even to producers of LLMs themselves, because this frontier is expanding and changing. According to the research performed, on tasks within the frontier AI significantly improved human performance. Outside of it, humans relied too much on the AI and were more likely to make mistakes. Not all users navigated the uneven frontier with equal adeptness. Understanding the characteristics and behaviors of these participants may prove important, as organizations think about ways to identify and develop talent for effective collaboration with AI tools.
Two predominant models that encapsulate human approach to AI could be identified, according to the Harvard and MIT research. The first is Centaur behavior: this approach involves a similar strategic division of labor between humans and machines closely fused together. Users with this strategy switch between AI and human tasks, allocating responsibilities based on the strengths and capabilities of each entity. They discern which tasks are best suited for human intervention and which can be efficiently managed by AI. The second approach is Cyborg behavior. In this stance users don’t just delegate tasks; they intertwine their efforts with AI at the very frontier of capabilities.
Upon identifying tasks outside the frontier, performance decreases were observed as a result of AI. Professionals who had a negative performance when using AI tended to blindly adopt its output and interrogate it less. Navigating the frontier requires expertise, which will need to be built through formal education, on-the-job training, and employee-driven up-skilling. Moreover, the optimal AI strategy might vary based on a company’s production function. While some organizations might prioritize consistently high average outputs, others might value maximum exploration and innovation.
Overall, AI seems poised to significantly impact human cognition and problem-solving ability. Similarly to how the internet and web browsers dramatically reduced the marginal cost of information sharing, AI may also be lowering the costs associated with human thinking and reasoning.
The era of generative AI is just beginning. Excitement over this technology is palpable, and earlypilots are compelling. It is extremely complex to forecast the adoption curves of this technology. According to historical findings, technologies take 8 to 27 years from commercial availability to reach a plateau in adoption. Some argue that the adoption of generative AI will be faster due to the ease of deployment. For McKinsey, it will be needed a minimum of eight years -in its earliest scenario- for reaching a global plateau in adoption.
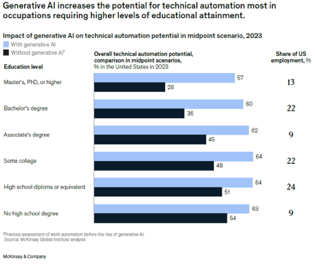
One final note about the labor impact of GenAI: economists have often noted that the deployment of automation technologies tends to have the most impact on workers with the lowest skill levels -as measured by educational attainment-, or what is called skill biased. From the McKinsey analysis, we can reach the conclusion that generative AI has the opposite pattern—it is likely to have the most incremental impact through automating some of the activities of more-educated workers:
Notwithstanding, a full realization of the technology’s benefits will take time, and leaders in business and society still have considerable challenges to address. These include managing the risks inherent in generativeAI, determining what new skills and capabilities the workforce will need, and rethinking core business processes such as retraining and developing new skills.
CICERO is an AI agent that can use language to negotiate, persuade, and work with people to achieve strategic goals similar to the way humans do. It was the first AI to achieve human-level performance in the strategy game No-press Diplomacy.
No-press Diplomacy is a complex strategy game, involving both cooperation and competition, that has served as a benchmark for multi-agent AI research. It is a 7-player zero-sum cooperative/competitive board game, featuring simultaneous moves and a heavy emphasis on negotiation and coordination. In the game a map of Europe is divided into 75 provinces. 34 of these provinces contain supply centers, and the goal of the game is for a player to control a majority (18) of the SCs. Each players begins the game controlling three or four supply centers and an equal number of units. Importantly, all actions occur simultaneously: players write down their orders and then reveal them at the same time. This makes Diplomacy an imperfect-information game in which an optimal policy may need to be stochastic in order to prevent predictability.
Diplomacy is a game about people rather than pieces. It is designed in such a way that cooperation with other players is almost essential to achieve victory, even though only one player can ultimately win. It requires players to master the art of understanding other people’s motivations and perspectives; to make complex plans and adjust strategies; and then to use natural language to reach agreements with other people and to persuade them to form partnerships and alliances.
How Was Cicero Developed by FAIR?
In two-player zero-sum (2p0s) settings, principled self-play algorithms ensures that a player will not lose in expectation regardless of the opponent’s strategy, as exposed by John von Neumann in 1928 in his work Zur Theorie der Gesellschaftsspiele.
Theoretically, any finite 2p0s game -such as chess, go, or poker- can be solved via self-play given sufficient computing power and memory. However, in games involving cooperation, self-play alone no longer guarantees good performance when playing with humans, even with infinite computing power and memory. The clearest example of this is language. A self-play agent trained from scratch without human data in a cooperative game involving free-form communication channels would almost certainly not converge to using English, for instance, as the medium of communication. Owing to this, the afore-mentioned researchers developed a self-play reinforcement learning algorithm -named RL-DiL-piKL-, that provided a model of human play while simultaneously training an agent that responds well to this human model. The RL-DiL-piKL was used to train an agent, named Diplodocus. In a 200-game No-press Diplomacy tournament involving 62 human participants, two Diplodocus agents both achieved a higher average score than all other participants who played more than two games, and ranked first and third according to an Elo rating system -a method for calculating the relative skill levels of players in zero-sum games.
Which Are the Implications of this Breakthrough?
Despite almost silenced by the advent of GPT in its different versions, firstly this is an astonishing advance in the field of negotiation, and more particularly in the realm of diplomacy. Never an AI model has had such a brilliant performance in a fuzzy environment, seasoned by information asymmetries, common sense reasoning, ambiguous natural language, and statistical modeling. Secondly and more importantly, this is another evidence we are in a completely new AI era in which machines can and are scaling knowledge.
These LLMs have caused a deep shift: we went from attempting to encode human-distilled insights into machines to delegating the learning process itself to machines. AI is ushering in a world in which decisions are made in three primary ways: by humans (which is familiar), by machines (which is becoming familiar), and by collaboration between humans and machines (which is not only unfamiliar but also unprecedented). We will begin to give AI fewer specific instructions about how exactly to achieve the goals we assign it. Much more frequently we will present AI with ambiguos goals and ask: “How, based on your conclusions, should we proceed?”
AI promises to transform all realms of human experience. And the core of its transformations will ultimately occur at the philosophical level, transforming how humans understand reality and our roles within it. In an age in which machines increasingly perform tasks only humans used to be capable of: what, then, will constitute our identity as human beings?
With the rise of AI, the definition of the human role, human aspirations, and human fulfillment will change. For humans accustomed to monopoly on complex intelligence, AI will challenge self-perception. To make sense of our place in this world, our emphasis may need to shift from the centrality of human reason to the centrality of human dignity and autonomy. Human-AI collaboration does not occur between peers. Our task will be to understand the transformations that AI brings to human experience, the challenges it presents to human identity, and which aspects of these developments require regulation or counterbalancing by other human commitments.
The AI revolution has come to stay. Unless we develop new concepts to explain, interpret, and organize its consequent transformations, we will be unprepared to navigate them. We must rely on our most solid resources -reason, moral and ethical values, tradition…- to adapt our relationship with reality so it keeps on being human.
The year has gotten off to a bad start for many families.
On January 5th, Amazon announced that it would lay off 18,000 employees. Days later Google stated it would lay off 12,000 employees; and the last to join the merry-go-round was Microsoft, which announced on January 18th that it would lay off 10,000 people. Twitter kicked things off when, in November last year, it announced the layoff of almost 4,000 employees.
What’s going on in the industry? I am not going to be the one to do an in-depth analysis -which has already been done- of the economic and financial reasons that have led these companies to make these decisions. What is clear is that, sad as it may seem, some positions made little or no sense at all from a business point of view (Chief Happiness Officer!), and the labor market in this sector was totally “overheated” concerning salaries with all the cash volume that both governments and central banks -directly or indirectly- had pumped into the economy.
However, let’s move on to a reflection that has gone somewhat unnoticed these days and which is the one that interests me: has or will the progressive implementation of AI in these companies have anything to do with these layoffs? Before pondering on it and answering…Blue pill or red pill? As always, red pill.
As happened in the first and second industrial revolutions with the steam engine, electricity, the telephone or the radio, we have before us a new and likely the most general of all general-purpose technologies: artificial intelligence. AI is not only an innovation itself, but also one that triggers cascades of complementary innovations, from new products to new production systems.
In both the first and the second industrial revolution, there were initial phases of adaptation that meant job losses for thousands of workers, since their jobs and skills no longer made any sense in the new economic scenario. And this is where we begin to go deeper into the analysis: automatization versus augmentation.
Let’s be positive, at least from the outset: both automation and augmentation can boost labor productivity. Nevertheless what happens with automation is that, as machines become better substitutes for human labor, workers lose economic and political bargaining power and become increasingly dependent on those who control the technology and on their financial business plans.
How are we envisioning AI nowadays? Towards automation or augmentation? There are many who deem AI should be focused on augmenting humans rather than mimicking them. Augmentation through AI creates new capabilities and new products and services, ultimately generating far more value than merely automating human tasks. In this approach humans and machines become complements. Complementarity implies that people remain indispensable for value creation and, when humans are indispensable, economic power and political decision-making tend to be more decentralized and democratized.
Nonetheless, there are currently excess incentives for automation rather than augmentation among technologists, business executives, and policy-makers. When AI replicates and automates existing human capabilities, it tends to reduce the marginal value of workers’ contributions, and more of the gains go to the owners, entrepreneurs, inventors, and architects of the new systems. Entrepreneurs and executives who have access to those AI models can and often will replace humans in those tasks.
There are some voices which defend a fully automated economy, such as one which could, in principle, be structured to redistribute the benefits from production widely, even to those people who are no longer strictly necessary for value creation. However, the beneficiaries’ incomes would depend on the decisions of those in control of the technology. This opens the door to increased concentration of wealth and power.
What is the solution regarding this dilemma? Clearly it is not slowing down technology, but from my standpoint rather eliminating the excess incentives for automation over augmentation. Think for instance on the US tax legislation, it encourages capital investment over investment in labor through effective tax rates that are much higher on labor than on plants and equipment. The US tax code treats labor income more harshly than capital income.
As a conclusion, the more technology is used to replace rather than augment labor, the worse the disparity may become. At the same time, automating a whole job is often extremely complex. Every job involves multiple different tasks, including some really challenging to automate. Think on industries such as health, legal, domestic security…
As mentioned once in a workshop, human beings and AI models should be -using the image of the Greek mythology- centaurs: a perfectly coordinated and unbeatable mix of wisdom and power.
Let’s see if, for once, we can think on the general benefit.
More than the quasi-human interaction and the practically infinite use cases that could be covered with it, OpenAI’s ChatGPT has provided an ontological jolt of a depth that transcends the realm of AI itself.
Large language models (LLMs), such as GPT-3, YUAN 1.0, BERT, LaMDA, Wordcraft, HyperCLOVA, Megatron-Turing Natural Language Generation, or PanGu-Alpha represent a major advance in artificial intelligence and, in particular, toward the goal of human-like artificial general intelligence. LLMs have been called foundational models; i.e., the infrastructure that made LLMs possible –the combination of enormously large data sets, pre-trained transformer models, and the requirement of significant computing power– is likely to be the basis for the first general purpose AI technologies.
In May 2020, OpenAI released GPT-3 (Generative Pre-trained Transformer 3), an artificial intelligence system based on deep learning techniques that can generate text. This analysis is done by a neural network, each layer of which analyzes a different aspect of the samples it is provided with; e.g., meanings of words, relations of words, sentence structures, and so on. It assigns arbitrary numerical values to words and then, after analyzing large amounts of texts, calculates the likelihood that one particular word will follow another. Amongst other tasks, GPT-3 can write short stories, novels, reportages, scientific papers, code, and mathematical formulas. It can write in different styles and imitate the style of the text prompt. It can also answer content-based questions; i.e., it learns the content of texts and can articulate this content. And it can grant as well concise summaries of lengthy passages.
OpenAI and the likes endow machines with a structuralist equipment: a formal logical analysis of language as a system in order to let machines participate in language. GPT-3 and other transformer-based language models stand in direct continuity with the linguist Saussure’s work: language comes into view as a logical system to which the speaker is merely incidental. These LLMs give rise to a new concept of language, implicit in which is a new understanding of human and machine. OpenAI, Google, Facebook, or Microsoft effectively are indeed catalyzers, which are triggering a disruption in the old concepts we have been living by so far: a machine with linguistic capabilities is simply a revolution.
Nonetheless, critiques have appeared as well against LLMs. The usual one is that no matter how good they may appear to be at using words, they do not have truelanguage; based on the primeval seminal trailblazing work from the philologist Zipf, criticism have stated they are just technical systems made up of data, statistics, and predictions.
According to the linguist Emily Bender, “a language model is a system for haphazardly stitching together sequences of linguistic forms it has observed in its vast training data, according to probabilistic information about how they combine, but without any reference to meaning: a stochastic parrot. Quite the opposite we, human beings, are intentional subjects who can make things into objects of thought by inventing and endowing meaning.“
Machine learning engineers in companies like OpenAI, Google, Facebook, or Microsoft have experimentally established a concept of language at the center of which does not need to be the human. According to this new concept, language is a system organized by an internal combinatorial logic that is independent from whomever speaks (human or machine). They have undermined one of the most deeply rooted axioms in Western philosophy: humans have what animals and machines do not have, language and logos.
Some data: monthly, on average, humans publish about seventy million posts on the content management platform WordPress. Humans produce about fifty-six billion words a month, or 1.8 billion words a day on this content management platform. GPT-3 -before its scintillating launch- was producing around 4.5 billion words a day, more than twice what humans on WordPress were doing collectively. And that is just GPT-3; there are other LLMs. We are exposed to a flood of non-human words. What will it mean to be surrounded by a multitude of non-human forms of intelligence? How can we relate to these astonishingly powerful content-generator LLMs? Do machines require semantics or even a will to communicate with us?
These are philosophical questions that cannot be just solved with an engineering approach. The scope is much wider and the stakes are extremely high. LLMs can, as well as master and learn our human languages, make us reflect and question ourselves about the nature of language, knowledge, and intelligence. Large language models illustrate, for the first time in the history of AI, that language understanding can be decoupled from all the sensorial and emotional features we, human beings, share with each other. Gradually, it seems we are entering eventually a new epoch in AI.